load("d50.rda")
load("d100.rda")
load("d500.rda")
p_trigon <- matrix(c(1, 0,
cos(pi*2/3), sin(pi*2/3),
cos(-pi*2/3), sin(-pi*2/3),
0, 0,
0, 0,
0, 0), ncol=2, byrow=TRUE)
p_trigon <- orthonormalise(p_trigon)
dx500_p <- render_proj(dx500, p_trigon)
dx500_p_edges <- cbind(
rbind(dx500_p$data_prj[mx500[1],1:2],
dx500_p$data_prj[mx500[2],1:2],
dx500_p$data_prj[mx500[3],1:2]),
rbind(dx500_p$data_prj[mx500[2],1:2],
dx500_p$data_prj[mx500[3],1:2],
dx500_p$data_prj[mx500[1],1:2]))
colnames(dx500_p_edges) <- c("x_from", "y_from", "x_to", "y_to")
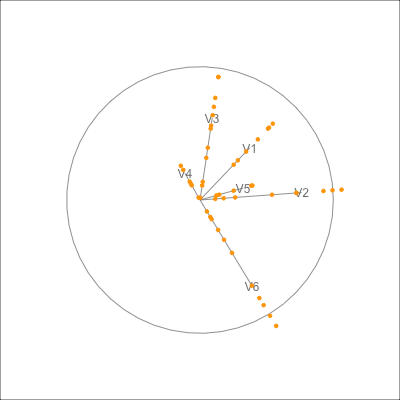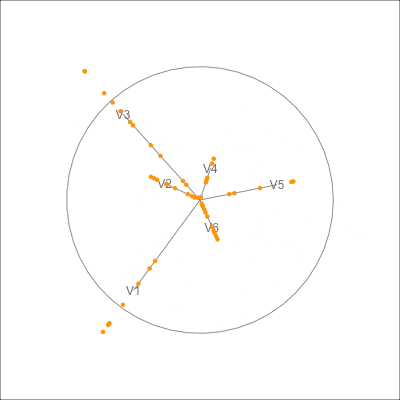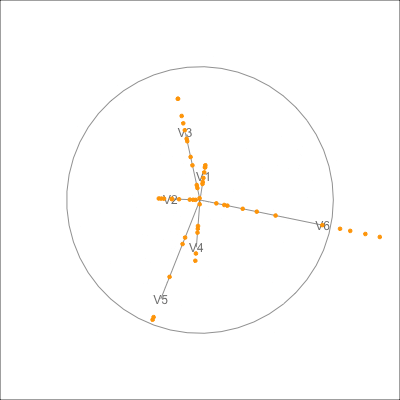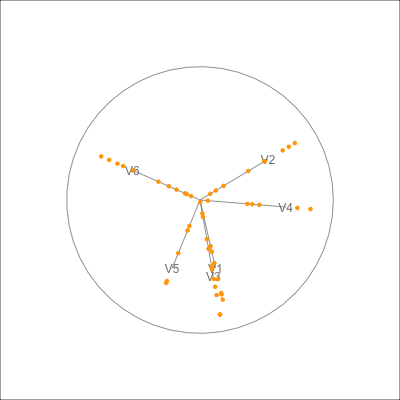
plt_tri <- ggplot() +
geom_point(data=dx500_p$data_prj, aes(x=P1, y=P2),
colour = "orange") +
geom_path(data=dx500_p$circle, aes(x=c1, y=c2)) +
geom_segment(data=dx500_p$axes, aes(x=x1, y=y1, xend=x2, yend=y2)) +
geom_text(data=dx500_p$axes, aes(x=x2, y=y2, label=rownames(dx500_p$axes))) +
geom_segment(data=dx500_p_edges,
aes(x=x_from, y=y_from,
xend=x_to, yend=y_to),
colour = "orange") +
xlim(-1,1) + ylim(-1, 1) +
theme_bw() +
theme(aspect.ratio=1,
axis.text=element_blank(),
axis.title=element_blank(),
axis.ticks=element_blank(),
panel.grid=element_blank())
p_4gon <- matrix(c(1, 0,
cos(pi*2/4), sin(pi*2/4),
cos(2*pi*2/4), sin(2*pi*2/4),
cos(-pi*2/4), sin(-pi*2/4),
0, 0,
0, 0), ncol=2, byrow=TRUE)
p_4gon <- orthonormalise(p_4gon)
dx500_p <- render_proj(dx500, p_4gon)
dx500_p_edges <- cbind(
rbind(dx500_p$data_prj[mx500[1],1:2],
dx500_p$data_prj[mx500[2],1:2],
dx500_p$data_prj[mx500[3],1:2],
dx500_p$data_prj[mx500[4],1:2]),
rbind(dx500_p$data_prj[mx500[2],1:2],
dx500_p$data_prj[mx500[3],1:2],
dx500_p$data_prj[mx500[4],1:2],
dx500_p$data_prj[mx500[1],1:2]))
colnames(dx500_p_edges) <- c("x_from", "y_from", "x_to", "y_to")
plt_quad <- ggplot() +
geom_point(data=dx500_p$data_prj, aes(x=P1, y=P2),
colour = "orange") +
geom_path(data=dx500_p$circle, aes(x=c1, y=c2)) +
geom_segment(data=dx500_p$axes, aes(x=x1, y=y1, xend=x2, yend=y2)) +
geom_text(data=dx500_p$axes, aes(x=x2, y=y2, label=rownames(dx500_p$axes))) +
geom_segment(data=dx500_p_edges,
aes(x=x_from, y=y_from,
xend=x_to, yend=y_to),
colour = "orange") +
xlim(-1,1) + ylim(-1, 1) +
theme_bw() +
theme(aspect.ratio=1,
axis.text=element_blank(),
axis.title=element_blank(),
axis.ticks=element_blank(),
panel.grid=element_blank())
p_5gon <- matrix(c(1, 0,
cos(pi*2/5), sin(pi*2/5),
cos(2*pi*2/5), sin(2*pi*2/5),
cos(3*pi*2/5), sin(3*pi*2/5),
cos(-pi*2/5), sin(-pi*2/5),
0, 0), ncol=2, byrow=TRUE)
p_5gon <- orthonormalise(p_5gon)
dx500_p <- render_proj(dx500, p_5gon)
dx500_p_edges <- cbind(
rbind(dx500_p$data_prj[mx500[1],1:2],
dx500_p$data_prj[mx500[2],1:2],
dx500_p$data_prj[mx500[3],1:2],
dx500_p$data_prj[mx500[4],1:2],
dx500_p$data_prj[mx500[5],1:2]),
rbind(dx500_p$data_prj[mx500[2],1:2],
dx500_p$data_prj[mx500[3],1:2],
dx500_p$data_prj[mx500[4],1:2],
dx500_p$data_prj[mx500[5],1:2],
dx500_p$data_prj[mx500[1],1:2]))
colnames(dx500_p_edges) <- c("x_from", "y_from", "x_to", "y_to")
plt_pent <- ggplot() +
geom_point(data=dx500_p$data_prj, aes(x=P1, y=P2),
colour = "orange") +
geom_path(data=dx500_p$circle, aes(x=c1, y=c2)) +
geom_segment(data=dx500_p$axes, aes(x=x1, y=y1, xend=x2, yend=y2)) +
geom_text(data=dx500_p$axes, aes(x=x2, y=y2, label=rownames(dx500_p$axes))) +
geom_segment(data=dx500_p_edges,
aes(x=x_from, y=y_from,
xend=x_to, yend=y_to),
colour = "orange") +
xlim(-1,1) + ylim(-1, 1) +
theme_bw() +
theme(aspect.ratio=1,
axis.text=element_blank(),
axis.title=element_blank(),
axis.ticks=element_blank(),
panel.grid=element_blank())
p_6gon <- matrix(c(1, 0,
cos(pi*2/6), sin(pi*2/6),
cos(2*pi*2/6), sin(2*pi*2/6),
cos(3*pi*2/6), sin(3*pi*2/6),
cos(4*pi*2/6), sin(4*pi*2/6),
cos(-pi*2/6), sin(-pi*2/6)), ncol=2, byrow=TRUE)
p_6gon <- orthonormalise(p_6gon)
dx500_p <- render_proj(dx500, p_6gon)
dx500_p_edges <- cbind(
rbind(dx500_p$data_prj[mx500[1],1:2],
dx500_p$data_prj[mx500[2],1:2],
dx500_p$data_prj[mx500[3],1:2],
dx500_p$data_prj[mx500[4],1:2],
dx500_p$data_prj[mx500[5],1:2],
dx500_p$data_prj[mx500[6],1:2]),
rbind(dx500_p$data_prj[mx500[2],1:2],
dx500_p$data_prj[mx500[3],1:2],
dx500_p$data_prj[mx500[4],1:2],
dx500_p$data_prj[mx500[5],1:2],
dx500_p$data_prj[mx500[6],1:2],
dx500_p$data_prj[mx500[1],1:2]))
colnames(dx500_p_edges) <- c("x_from", "y_from", "x_to", "y_to")
plt_hex <- ggplot() +
geom_point(data=dx500_p$data_prj, aes(x=P1, y=P2),
colour = "orange") +
geom_path(data=dx500_p$circle, aes(x=c1, y=c2)) +
geom_segment(data=dx500_p$axes, aes(x=x1, y=y1, xend=x2, yend=y2)) +
geom_text(data=dx500_p$axes, aes(x=x2, y=y2, label=rownames(dx500_p$axes))) +
geom_segment(data=dx500_p_edges,
aes(x=x_from, y=y_from,
xend=x_to, yend=y_to),
colour = "orange") +
xlim(-1,1) + ylim(-1, 1) +
theme_bw() +
theme(aspect.ratio=1,
axis.text=element_blank(),
axis.title=element_blank(),
axis.ticks=element_blank(),
panel.grid=element_blank())
plt_tri + plt_quad + plt_pent + plt_hex + plot_layout(ncol=4)